Geocoding Families of the Single Registry in Campinas-SP
Introduction
Any institution that aims to contribute to social transformation wonders what information to collect and how best to read the territory, especially the social vulnerability of its population. At the intra-municipality level, the main source of data is the Demographic Census, which still has huge expectations surrounding the release of the microdata and data aggregated by census tract. Even though it is an essential and irreplaceable source, the decennial period imposes the challenge of seeking alternatives that allow more frequent readings and are therefore adherent to the eternally changing social situation.
With this goal, the two institutions, FEAC Foundation and Pontifical Catholic University of Campinas Observatory, started to invest in the treatment and analysis of the Single Registry (CadÚnico) which, According to the Secretary for Assessment, Information Management and Single Registry, consists of an identification and socioeconomic characterization of low-income Brazilian families, recording information on household characteristics, education, family composition, work and income, among others. It is worth mentioning that its use for study and research purposes is regulated by decree and requires ethical demands to be met in handling information.
Methodology
The first task imposed by the Single Registry (CadÚnico) was related to the structure of the addresses. With the main problems related to the literature, such as misspellings, abbreviations, and missing information, being non-standard overall. This directly impacts the geocoding process, which receives the address as an input and gives geographical coordinates as an output.
It was also learned from the literature that each geocoding service tends to produce different quality geographical outputs in distinct regions of the municipality. When dealing with sensitive data, especially at the municipality level, the precision of the geocoding is crucial, similar to the analysis imposed in Epidemiological and health studies.
To address these problems, many techniques were used, mainly the first being to minimize the problem with non-standard addresses, as presented in the Single Registry Data. For that, the National Directory Address (NDA) was used. The Correios is a public institution that deals with package delivery at the national level and has information in standard form about every official address, including all the main components.
With the data in hand, the geocoding process begins with three main services (Arcgis, Google, Bing). The main idea was to build a process to select the best coordinates, surpassing the problems with quality in distinct regions within the municipality. One of the problems with the comparison was that each service gave a different metric of quality. Google and Bing provide a categorical metric, while Arcgis gives a Numerical one.
Because of that, the Zip Code worked as the main variable of quality, alongside a tiebreaker methodology called the Method of Double Confirmation (MDC). It was learned in the literature that the Zip Code represents a stable variable that summarizes the main components of the address in a single code and is not susceptible to typos, mistakes, abbreviations, and others, like the addresses, being used as a linked variable between the Single Registry and NDA data sets.
The MDC, on the other hand, works as a tiebreaker, hierarchizing the geocoding services by the confirmation of coordinates obtained for each service. In sum, if each service returns a coordinate for a unique address, giving three comparable coordinates, the method would seek to compare the linear distance in kilometers between the coordinates, picking the two closest and assigning a point for each. If just two services were able to provide coordinates for an address, they would also receive a point each because they confirmed each other. If there were just one service that returned a coordinate, it would not receive a point. In the end, the frequency of each service would create a global ranking of quality.
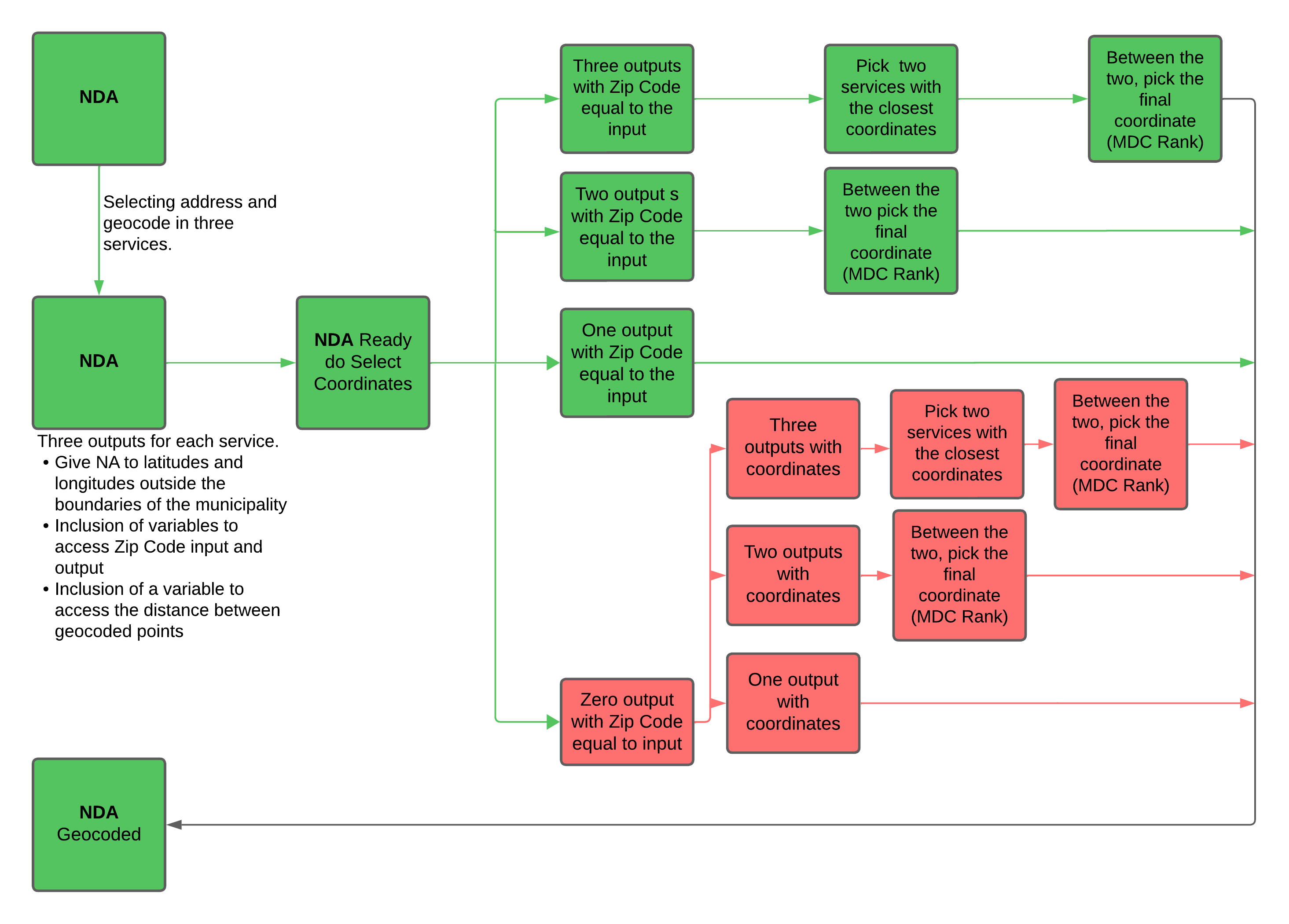
To select the best suitable coordinates for each address, the methodology first looks at the Zip Code that was given in the input address and the output Zip Code for each service. If the three services give the same Zip Code in the input and output, the selection process would continue to analyze the linear distance in kilometers, picking the two closest services. Finally, the MDC global rank would break the tie between them, picking a final coordinate.
In the case of only two services providing the output with the same Zip Code as the input, the process falls directly under the MDC tiebreaker because distance is not comparable. If just one service gives an output with the same Zip Code as the input, that would be selected as the final coordinate.
When no service meets the Zip Code criteria, the methodology goes directly to the compared distances and the MDC tie brake. When there are three outputs, the distance is looked at, and then the tiebreaker happens. If there are just two services, the tiebreaker will happen directly. In the case of only one service, this is considered final. Every step can be viewed in the flow chart bellow.
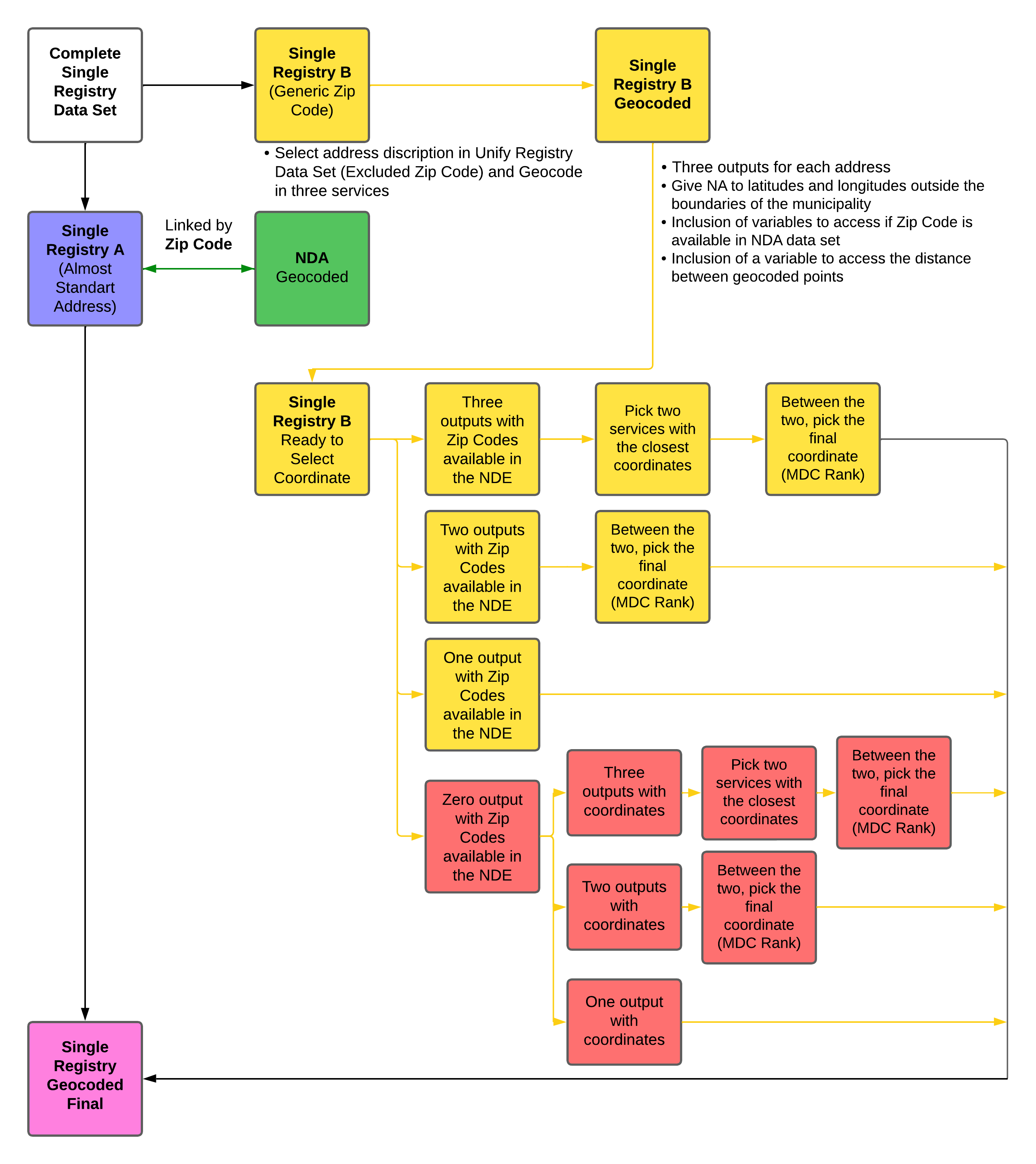
After the geocoding of the NDA data set, the coordinates will be donated to the Single Registry data set, which is linked by Zip Code, and contains the families. One problem was discovered in the Single Registry data set related to the Zip Code that was being assigned to families, but it did not correspond to the address that was input to them. This was later called a “generic Zip Code”, because the information was not related to the original address. This most likely occurred because many families lived in areas that were occupied, so there was no official address by the Correio, meaning that to fill in the registry, a generic Zip Code was given.
For these families, a new Geocoding was needed, using only the information available in the Single Registry data set, which is non-standard and has two levels of information missing: the Zip Code and the house number. The workflow basically divided the Single Registry data set in two, the first with an almost standard address, meaning that families were able to receive the donation coordinate from the NDA by the Zip Code. The other was the family with a generic Zip Code, which needed a new round of geocoding because the linkage with the Zip Code was not possible.
The identification of these families was made based on the frequency of Zip Code in the Single Registry data set. Those Zip Code with more than 200 frequencies were geocoded in the rank-one service of the MDC. The goal was to compare the Zip Code assigned to those in the input addresses to the output given. If they were the same, no point would be assigned; if not, a point would be counted, and the final frequency would give a view if the input addresses with the Zip Code returned a different Zip Code.
The process to pick the final coordinates for those addresses follows the same logic as the NDA geocoding. The main difference is that there is no comparison between the Zip Code inputs because they are not linked to the address. To resolve this issue, the confirmation procedure involved locating the output Zip Code, providing the input address, and examining whether the output Zip Code was included in the NDA data set. This worked as the first quality step. All the others follow the same principle as before, looking at the distance, picking the two closest, and tie braking by the MDC global rank. The finals step can be viewed in the flow chart bellow.
Results
The results for the NDA geocoding with 11.126 addresses show that the MDC global rank was given in the following order: Arcgis, Google and Bing. The confirmation of Zip Code given in the input and returned to the output was for at least one service, representing 87,74% of the total addresses.
About the quality performance, Arcgis is the best, finding the Zip Code confirmation in 73,56% of the total input addresses, followed by Google with 53,94% and similarly Bing with 52.55%. The final selection of coordinates for the NDA address was 8691 by Arcgis, 2062 by Google, and 368 in Bing.
A total of 6521 addresses were detected as being related to generic Zip Codes. The results show that 6231 addresses returned at least one output with a reference Zip Code found in the de NDA, even when the Zip Code was not used as input for this process, representing 95,49% of the total.
The quality performance in this step shows that Bing was more accurate with non-standard addresses, finding a reference Zip Code in the NDA for 87,66% of the total addresses, followed by Arcgis with 60,15% and Google with 48,91%.
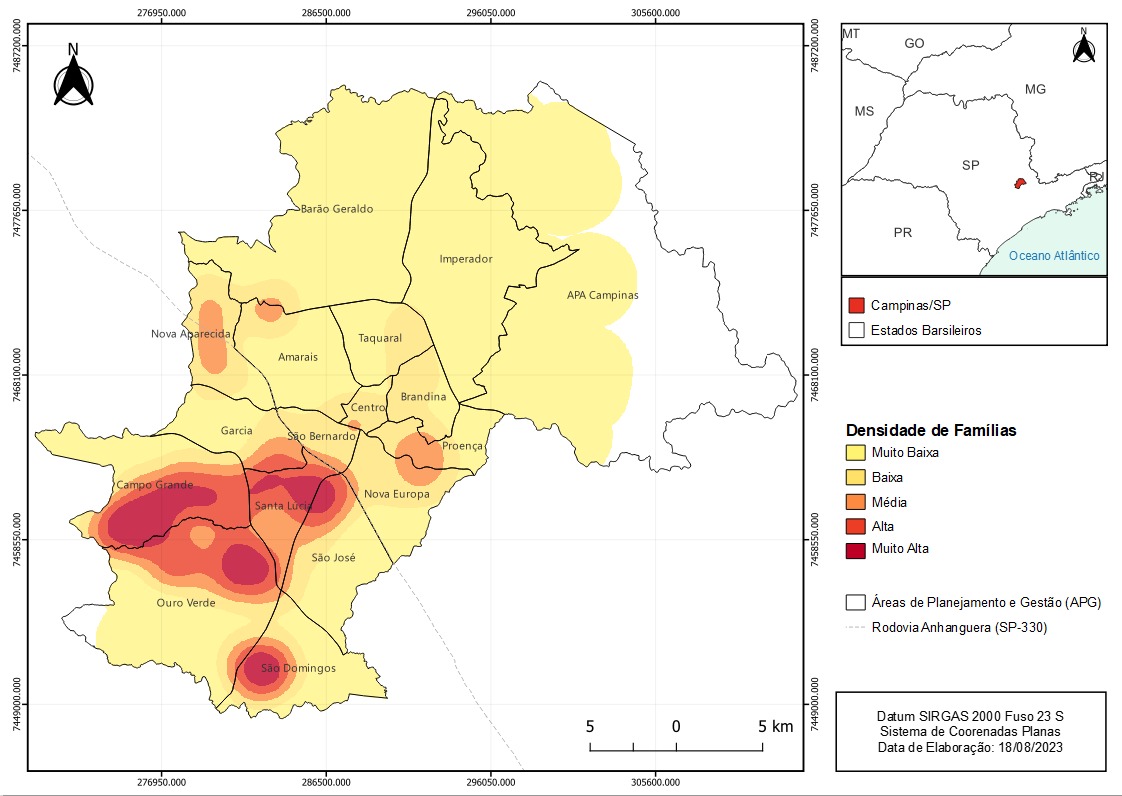
Finally, 71.452 of the 71.466 families managed to be geocoded. The map below shows the Kernel Density for the municipality, mapping the areas with a high frequency of registry families. The results entailed the segregation of the south area of Campinas-SP and the division made by Highway Anhanguera.